Vyākarana: A Colorless Green Benchmark for Syntactic Evaluation in Indic Languages
Abstract
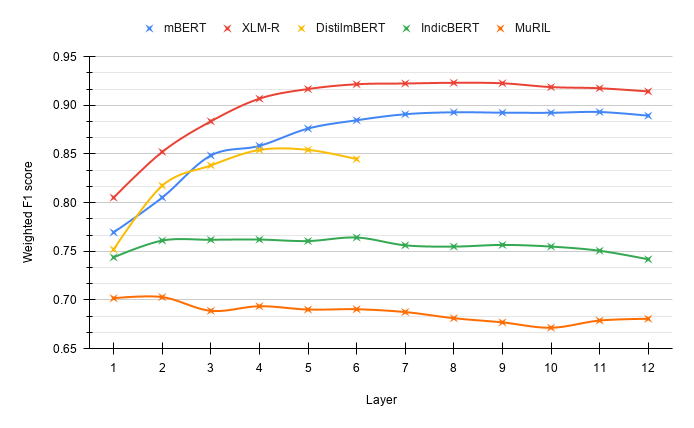
While there has been significant progress towards developing NLU resources for Indic languages, syntactic evaluation has been relatively less explored. Unlike English, Indic languages have rich morphosyntax, grammatical genders, free linear word-order, and highly inflectional morphology. In this paper, we introduce Vyākarana: a benchmark of Colorless Green sentences in Indic languages for syntactic evaluation of multilingual language models. The benchmark comprises four syntax-related tasks: PoS Tagging, Syntax Tree-depth Prediction, Grammatical Case Marking, and Subject-Verb Agreement. We use the datasets from the evaluation tasks to probe five multilingual language models of varying architectures for syntax in Indic languages. Due to its prevalence, we also include a code-switching setting in our experiments. Our results show that the token-level and sentence-level representations from the Indic language models (IndicBERT and MuRIL) do not capture the syntax in Indic languages as efficiently as the other highly multilingual language models. Further, our layer-wise probing experiments reveal that while mBERT, DistilmBERT, and XLM-R localize the syntax in middle layers, the Indic language models do not show such syntactic localization.