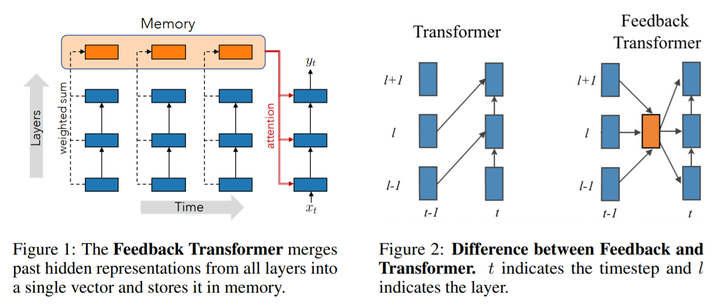
 Image taken from the Feedback Transformer paper - https://arxiv.org/abs/2002.09402
Image taken from the Feedback Transformer paper - https://arxiv.org/abs/2002.09402
Table of Contents
My final project submission for the Meta Learning course at BITS Goa (conducted by TCS Research & BITS Goa). The project is based on the Feedback Transformer paper. The paper introduces a feedback mechanism in transformer models by adding a recurrent memory-attention based approach. This helps the transformer model in:
- Accessing higher level (layers) representations
- Maintaining a belief state
- Perform a learnable wieghted combined top-down and bottom-up processing
- Decrease compute memory-consumption at inference
The project can be run as a colab notebook ![]() , where the approach given in the paper can be understood in more detail through experimentation. The experiments' Tensorboard logs and a video explanation for the notebook can be found here.
, where the approach given in the paper can be understood in more detail through experimentation. The experiments' Tensorboard logs and a video explanation for the notebook can be found here.
Key Contributions
The key contributions of this project can be listed as follows:
- Implementing and Open-sourcing a modular customizable Feedback Transformer Model in PyTorch
- Experimenting the Feedback Transformer Model with COGS Benchmark (Compositional Generalization)
- Implementing the Sequence Copy & Reverse Task from the original Feedback Transformer Paper
Feedback Transformer Implementation
The Feedback Transformer Model has been implemented as PyTorch model class in the given notebook. You can adjust the various hyperparameters and turn the feedback ON/OFF in the Encoder and Decoder of the Model independently. Use the model in the following manner:
model = FeedbackTransformerModel(
encoder_feedback = False, # Disable Feedback Mehancism in the Encoder
decoder_feedback = True, # Enable Feedback Mehancism in the Decoder
memory_context = 8, # How long to look in the past for Memory-attention
input_vocab_size = 800, # Input Vocabulary Size
output_vocab_size = 800, # Output Vocabulary Size
d_model = 128, # Model Embedding Dimension
nhead = 8, # Number of Heads in Multi-head Cross-attention and Memory-attention
num_layers = 4, # Number of Encoder and Decoder blocks
dim_feedforward = 256, # Feedforward Dimension
max_seq_length = 1000, # Maximum Sequence Length in Data
dropout = 0.1, # Model Dropout Probability
PAD_IDX = 0, # PAD Token ID to Mask Padding tokens for Attention
activation = "gelu", # Model Activation Function: "gelu" / "relu"
)
Solving COGS with Feedback Transformer
The COGS Benchmark is a benchmark for evaluating compositional generalization & reasoning in natural language. The COGS task is that of mapping a natural language sentence to a lambda-expression based semantic logical form:
input_sentence = "The moose wanted to read ."
output_logical_form = "* moose ( x _ 1 ) ; want . agent ( x _ 2 , x _ 1 ) AND want . xcomp ( x _ 2 , x _ 4 ) AND read . agent ( x _ 4 , x _ 1 )"
This can be treated as a sequence-to-sequence semantic-parsing task. What makes this task challenging is its Generalization test set. The following points make it quite challenging:
- Novel (unseen in training) Combination of Familiar Primitives and Grammatical Roles
- Novel (unseen in training) Combination Modified Phrases and Grammatical Roles
- Deeper Recursion (results in longer sentences and deeper lingusitic strucutre i.e. parse tree)
- Verb Argument Structure Alternation
- Verb Class Alteration
You can check the COGS Paper for more details on the benchmark.
The COGS dataset can be loaded as a PyTorch-Lightning Module in the following manner:
datamodule = COGSDataModule(
batch_size=128, # Batch Size for Training
num_workers=2, # Number of workers for Data Loading
use_100=False, # Whether to use single-exposure or hundred-exposures for pimitives in the training set
use_Gen=True # Whether to use normal test set or generaliztion test set
)
NOTE: The feedback transformer paper does not include this benchmark or any related task. This is the first attempt (to the best of my knowledge) to inspect the effect of incoroporating feedback and memory based architectural biases in solving compositional generalization problem in natural language.
Results
While the PyTorch-Lightning profiler and Tensorboard logger (included in the notebook) will give a detailed insights into the experiments, here are key metrics to report:
| Encoder Feedback | Decoder Feedback | Num Parameters | Validation Accuracy | Generalization Accuracy | Total Training time | Mean Forward time | Mean Backward time | Inference time |
|---|---|---|---|---|---|---|---|---|
| False | False | 12.7k | 69.5% | 65.44% | 193.43 s | 22.58 ms | 25.17 ms | 20.08 ms |
| False | True | 12.3k | 74.1% | 70.86% | 4441.7 s | 645.08 ms | 1039.30 ms | 365.49 ms |
| True | True | 12.2k | 74.4% | 70.69% | 7402.4 s | 701.85 ms | 1129.4 ms | 404.65 ms |
NOTE: The results are subject to change in hyperparameters and training settings. The above results are obtained from the current settings given in the notebook. The results can be increased significantly by training bigger models for longer times.
Discussion
- The Validation accuracy (roughly equal to the Normal test accuracy) reflects the Expressivity of the models towards the COGS task
- Access to higher level representations might help in semantic-parsing by allowing top-down processing
- In general, incorporating feedback gives the model more expressivity with lesser number of parameters
- The Generalization test accuracy (usually lower than Validation and Normal test accuracy) reflects the Compositional Generalization capabilities of the models
- This needs accurate inference on previously unseen novel linguistic structures and an ability to maintain a belief state for longer contexts
- On an absolute scale, incorporating feedback increases the Generalization test accuracies significantly
- High Expressivity can lead to poor Compositional Generalization in Vanilla Transformer models (as reported in the COGS Paper)
- The Vanilla Transformer model (no feedback) shows a 5.84% decrease in accuracy between the Validation and Generalization test set
- Enabling feedback in Decoder reduces the drop in Generalization accuracy to 4.37%
- Enabling feedback in Encoder further reduces the the drop in Generalization accuracy to 4.98%
Sequence Copy & Reverse Task
The Sequence Copy & Reverse task is included in the Feedback Transformer paper as an Algorithmic task to test the role of memory in long-sequence processing. Since the official dataset is not publicly available, we generate the dataset synthetically.
The sequence copy & reverse dataset can be loaded as a PyTorch-Lightning Module in the following manner:
datamodule = SequenceCopyDataModule(
batch_size=64, # Batch Size for Training
num_workers=2, # Number of workers for Data Loading
num_samples_train=10000, # Number of samples to generate for training set
num_samples_eval=1000, # Number of samples to generate for validation and test set
max_length_train=10, # Sequence length in training samples
max_length_eval=50, # Sequence length in evaluation samples (Should be significantly longer to test for memory effect)
reverse=True, # Whether to Copy the Input Sequence or Reverse the Input Sequence
)
NOTE: The ablation analysis for this task with Feedback Transformer is still in progress. One can still train the Feedback Transformer for this task using the last section of the project’s colab notebook.
Citations
If you use the code in this repository in any manner, cite the repository:
@misc{patil2021-feedback-github,
author = {Rajaswa Patil},
title = {feedback-and-memory-in-transformers},
month = apr,
year = 2021,
publisher = {Github},
url = "https://github.com/rajaswa/feedback-and-memory-in-transformers"
}
If you use the code for Feedback Transfomer or the Sequence Copy & Reverse task, cite the Feedback Transformer paper:
@misc{fan2021addressing,
title={Addressing Some Limitations of Transformers with Feedback Memory},
author={Angela Fan and Thibaut Lavril and Edouard Grave and Armand Joulin and Sainbayar Sukhbaatar},
year={2021},
eprint={2002.09402},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
If you use the code from COGS Benchmark data processing and loading, cite the COGS paper:
@inproceedings{kim-linzen-2020-cogs,
title = "{COGS}: A Compositional Generalization Challenge Based on Semantic Interpretation",
author = "Kim, Najoung and
Linzen, Tal",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.731",
doi = "10.18653/v1/2020.emnlp-main.731",
pages = "9087--9105",
abstract = "Natural language is characterized by compositionality: the meaning of a complex expression is constructed from the meanings of its constituent parts. To facilitate the evaluation of the compositional abilities of language processing architectures, we introduce COGS, a semantic parsing dataset based on a fragment of English. The evaluation portion of COGS contains multiple systematic gaps that can only be addressed by compositional generalization; these include new combinations of familiar syntactic structures, or new combinations of familiar words and familiar structures. In experiments with Transformers and LSTMs, we found that in-distribution accuracy on the COGS test set was near-perfect (96{--}99{\%}), but generalization accuracy was substantially lower (16{--}35{\%}) and showed high sensitivity to random seed (+-6{--}8{\%}). These findings indicate that contemporary standard NLP models are limited in their compositional generalization capacity, and position COGS as a good way to measure progress.",
}
Contact
Submit an issue here.
Rajaswa Patil
Research Fellow
My research interests include natural language processing, program synthesis, ai4code.